Abstract
Drug design, referred to the fields of pharmacology, biotechnology and medicine, is in silico, in vitro and in vivo assay processes of finding new candidate medications based on the biological targets. The in silicoexperiments of drug discovery are involved in the macromolecular structure databases, small molecule databases, molecular docking, de novo drug design and molecular dynamics simulations. The in vitro experiments of drug discovery need evaluate the direct interaction information between ligands and targets as well as the function of ligands on signaling pathway in the cell. The in vivo experiments of drug discovery give the convincing evidence for preclinical trial at the physiological level. In this review, we outline the drug design components of databases, virtual screening tools, biochemical assays, cell-based system and animal models.
Author Contributions
Academic Editor: George Kordas, Twice ERC laureate (Nanotherapy Advanced Grant and PoC Grant) ERC LS7 Panel Member, Member of the ASF 15 Panel
Checked for plagiarism: Yes
Review by: Single-blind
Copyright © 2018 Qifeng Bai,et al
 This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Competing interests
The authors have declared that no competing interests exist.
Citation:
Introduction
Modern new drug design is the integrated and long-term processes which will cost tens to hundreds of millions dollars from candidate compounds trial to Food and Drug Administration (FDA) approval1. The preclinical drug design trial can be made of in silico, in vitro, and in vivo experiments. The development of information technology and big data accelerate the speed of drug discovery because the high effective and targeted databases are constructed under these circumstances2. The famous databases designed for drug discovery are introduced in detail following review part. Based on the accurate structural models of biological targets and small molecules, the molecular docking software3 can be used to estimate the affinity of ligand in the pocket of biological macromolecules. In addition, the de novo method is another computer-aided design for new drug generation on basis of 3D-structural targets and pharmacophore model4. To study the dynamical interaction between receptors and ligands at the atomic level, the molecular dynamics (MD) simulations supply a reliable and accurate way to explore the binding mechanism between ligands and targets5, 6. Our review describes the popular molecular docking, de novo drug and MD simulation software in drug discovery field. The candidate compounds screened in silico still need be validated to make sure the compound has pharmaceutical activity. The direct binding experiment in vitro between ligands and targets should be trial by using the methods of X-ray crystallography structural analysis, Surface Plasmon Resonance (SPR), etc7. Because the direct binding assay cannot guarantee the activity of screened ligands, the cell signaling pathway response experiment should be performed to check the activity of ligands in cell8. Due to the complex physiological environment, the active ligands in vitro trial may not show any response to the targeting disease in vivo. Hence, it need choose the suitable animal models for in vivo experiments9. In this review, we introduce the database, in silico drug design software, in vitro experiment,and in vivo animal models (see Figure 1). Of course, the sequence of in silico, in vitro and in vivo experiments can be changed according to specific conditions. For instance, if the animal models are easier to be got and cheaper to be bought than biochemical assays, the in vivo experiments can be placed before the in vitro trial. Generally, our review gives the researchers an easy understanding contour for drug design.
Figure 1. The diagram of in silico, in vitro and in vivo for drug design.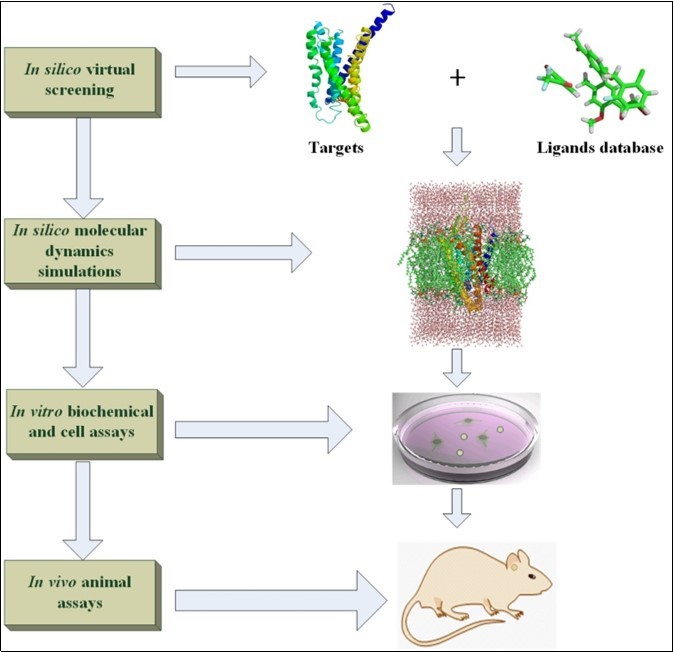
In silico Database for Drug Design
With the development of bioinformatics, big data, biology, chemistry and medicine, more and more databases are design to service for the drug discovery10. The databases are divided into macromolecular and small molecular databases. The macromolecular structure databases contain the crystal structures of proteins, nucleic acids, or other biopolymers. Table 1 shows the popular databases of macromolecular crystal structures and theoretical 3D macromolecular structures by homology modeling method. The wwPDB11 currently contains three Protein Data Bank (PDB) databases and one Biological Magnetic Resonance Data Bank which are RCSB PDB, PDBe, PDBj, and BMRB, respectively. The RCSB PDB database is a three dimensional (3D) structural crystallographic database for large biological molecules such as proteins and nucleic acids12 which are collected from NMR spectroscopy, X-ray crystallography, and cryo-electron microscopy13, 14. The databases of PDBe and PDBj lay in Europe and Japan are another two organizations which are responsible for the collection and dissemination of biological macromolecular structures. The Biological Magnetic Resonance Data Bank (BMRB) focuses on the data collection of NMR Spectroscopy from peptides, proteins, nucleic acids, and other biomolecules. Nucleic Acid Database (NDB)15 recruits the functions, structures, analysis, and sequences of experimentally-determined nucleic acids. Molecular Modeling Database (MMDB)16 collects experimentally resolved three-dimensional biomolecule structures under the maintenance of National Center for Biotechnology Information. JenaLib database17 emphasizes the visualization and analysis of three-dimensional biopolymer structures. PDBbind database18, 19 is interested in collecting the experimental binding affinity data. The molecular docking scores can be developed on basis of the collected data of Kd, Ki, and IC50 in PDBbind database. Generally, these macromolecular databases accelerate the drug discovery via providing accuracy and rich structural information, especially, the crystal target data in complex with ligands. Based on the accuracy crystal information, the successful drug screenings and mechanism studies are reported on the targets of transcription factor20, G protein-coupled receptors (GPCRs)21,22,23, transporter24, ion channels receptors25, and so on. IUPHAR/BPS Guide to PHARMACOLOGY26, 27 provides the information of clinical, approved drugs and candidate compounds for the popular targets such as GPCRs, ion channels receptors, kinases, transporters, and so on. It is very simple for users to find the drug comprehensive resources which contain 3D crystal structure targets, relative database links, bioactive ligands from literature, antibodies, functional assays, physiological functions, disease models and so on.
Table 1. Macromolecular structure databases| Structure databases | Description | Weblink |
| wwPDB | Worldwide macromolecular structures | www.wwpdb.org |
| RCSB PDB | Macromolecular structures | www.rcsb.org |
| PDBe | Macromolecular structures in Europe | www.ebi.ac.uk/pdbe |
| PDBj | Macromolecular structures in Japan | pdbj.org |
| BMRB | Macromolecular structures from NMR | www.bmrb.wisc.edu |
| NDB | Nucleic acid structure database | ndbserver.rutgers.edu |
| MMDB | 3D macromolecular structures | www.ncbi.nlm.nih.gov/Structure/MMDB/mmdb.shtml |
| JenaLib | 3D biopolymer structures | jenalib.leibniz-fli.de |
| PDBbind | 3D macromolecular structures in complex with ligands | www.pdbbind.org.cn |
| IUPHAR/BPS Guide to PHARMACOLOGY | Pharmacological targets and substances | www.guidetopharmacology.org |
| ModBase | Theoretical 3D macromolecular structures | modbase.compbio.ucsf.edu/modbase-cgi/index.cgi |
| PMP | Theoretical 3D macromolecular structures | www.proteinmodelportal.org |
| SWISS-MODEL | Theoretical 3D macromolecular structures | swissmodel.expasy.org/repository |
Until now, the number of proteins with crystal structures is limited because there are still some intractably unresolved crystal proteins and nucleic acids structures. The targets without the crystal structures cannot supply the accurate 3D models for drug discovery. In order to screen the candidate compounds based on the active sties of targets without crystal structure, it need predict the 3D structures from the sequence of proteins or nucleic acids. The ModBase28, PMP29, and SWISS-MODEL30 can help the researchers build the 3D theoretical models of targets by comparative modeling methods. The theoretical 3D macromolecular structures also give the reliable 3D models to screen the potential drugs from the large of small molecule database. Some studies have shown homology model can be considered as the valid target to perform the virtual screening31, 32. The crystal and predicted models have been widely applied into the research field of drug discovery.
Drug discovery not only needs the reliable models, but also is relied on huge of small molecules with reasonable conformations. Table 2 shows the popular and special purpose small molecule databases for drug discovery. ZINC database33, 34 is considered as an open-access commercially-available screening library which contains over 35 million purchasable small molecules for virtual screening. ZINC database, which supplies Lead-Like, Drug-Like, Fragment-Like for different research needs, has been reported to be used to screen the candidate compounds by molecular docking methods35, 36. PubChem database currently consists of compounds, substances and bioassay databases which recruit the 93.9 million, 249 million and 1.25 million entries, respectively. Therefore, PubChem37 database can be used to dig out the potential bio-activated compounds through molecular docking and deep learning studies. DrugBank38 is a comprehensive and open-access database containing detail information of drug data and drug targets. In combination with the ZINC database, it has been used to find the ligands via molecular docking based screening39, 40. The databases of ChemBridge, Specs and ChemDiv can supply with the commercially customized screening libraries for the drug development targeting to research receptors such as cyclophilin D41, p-Hydroxyphenylpyruvate dioxygenase (HPPD)42, SETDB1/ESET43, and so on. The e-Drug3D44 database recruits the 1852 molecular structures which approved by Food and Drug Administration (FDA) between 1939 and 2017 with a molecular weight ≤ 2000. The e-Drug3D can be used as the benchmark for finding the effective candidate compounds. Super Natural II45 is a database of natural compounds with physicochemical properties, predicted toxicity information, 2d structures, and vendors. In all, ~75% of FDA approved small molecular drugs are from natural compounds or its derivatives46. Hence, Super Natural II database has a good promising for drug development by in silico method. The Cambridge Structural Database (CSD)47 and Crystallography Open Database (COD)48 are mainly interested in the collection of small molecule organic and inorganic crystal structures. It cannot only be used for drug virtual screening, but also give the accurate structural information for other computing such as quantum chemical calculation. The KEGG Ligand database49 comprises COMPOUND, REACTION, and ENZYME which is responsible for collecting the chemical compounds, chemical reactions, and enzyme molecules, respectively. The nucleic acid ligand database (NALDB)50 and small molecule pathway database (SMPDB)51 are designed for the special purpose of drug discovery. The NALDB provides the detail experimental data of small molecules which target to nucleic acid structures. The SMPDB gives the ligands interactive network on signal pathway found in human which is used to elucidate the drug-action signaling pathways. The MarinChem3D (mc3d.qnlm.ac), which locates at National Laboratory for Marine Science and Technology (Qingdao) in China, publishes more than 30,000 well-defined 3D structures of marine natural products. It can be used to perform the virtual screening studies directly. The MarinChem3D gives a promising way to find candidate ligands targeting to receptors from the ocean.
Table 2. Small molecule databases| Ligand databases | Description | Weblink |
| ZINC | Over 35 million purchasable compounds for virtual screening | zinc.docking.org |
| PubChem | Over 90 million compounds | pubchem.ncbi.nlm.nih.gov |
| DrugBank | More than 11,000 drug entries | www.drugbank.ca |
| Specs | Providing high throughput screening compounds | www.specs.net |
| ChemBridge | Over 1.1 million druglike and leadlike compounds | www.chembridge.com/screening_libraries |
| ChemDiv | Over 1,5 M individual solid screening compounds | www.chemdiv.com/services-menu/screening-libraries |
| e-Drug3D | 1852 FDA approved drugs between 1939 and 2017 | chemoinfo.ipmc.cnrs.fr/MOLDB/index.html |
| Super Natural II | 325,508 natural compounds | bioinf-applied.charite.de/supernatural_new/index.php |
| CSD | Over 900,000 small-molecule organic crystal structures | www.ccdc.cam.ac.uk/solutions/csd-system/components/csd |
| COD | Over 390,000 inorganic crystals and small organic compounds | www.crystallography.net/cod |
| KEGG Ligand | Universe of chemical substances and reactions | www.genome.jp/kegg/ligand.html |
| NALDB | Nucleic acid ligand database | bsbe.iiti.ac.in/bsbe/naldb/HOME.php |
| SMPDB | Over 30,000 small molecule pathways found in humans | smpdb.ca |
| MarinChem3D | Over 30,000 kinds of marine compounds | mc3d.qnlm.ac |
In silico Software for Drug Design
Although the macromolecular structure and small molecule databases are an important factor for drug discovery in silico, it still needs the effective software for performing virtual screening on targets and small molecule databases. In the past decades, various molecular docking software emerges based on different algorithms and molecular formats. Generally, the computational methods for drug discovery can be divided into ligand-based (indirect) and structure-based (direct) techniques52. The ligand-based drug design methods contain quantitative structure-activity relationship (QSAR)53, pharmacophore54, etc. The structure-based drug design contains molecular docking and de novo methods. With the development of genomics and the accumulation of pharmacological information, the big data and deep learning have permeated into the drug discovery fields. For instance, the tensorflow55, which is a deep learning software library, has been used for the drug discovery and molecular dynamics simulations56. These popular computational methods have been integrated into different software for drug design. The QSAR and pharmacophore model can be constructed by Schrödinger or Discovery Studio software. The molecular docking software can be divided into free academic and commercial programs. Besides, molecular dynamics simulations57 are considered as the accurate and dynamical way to study the interaction between targets and ligands. Table 3 shows the free academic, commercial molecular docking programs and molecular dynamics simulations software. LeDock58 is designed based on CHARMM force field parameters by using simulated annealing search algorithm. LeDock shows the very high accuracy in pose prediction and is free for the purpose of academic use. rDock is an open source molecular docking program which can be used to dock ligands into the active sites of proteins and nucleic acids59. AutoDock Vina and AutoDock are two free academic programs for molecular docking. AutoDock can use the flexibility algorithm to dock the ligands into the proteins by Lamarckian genetic algorithm60, 61. AutoDock Vina, which is considered as the new generation of AutoDock, has faster run speed and more accurate binding mode predictions than AutoDock62. UCSF DOCK63 is the first molecular docking program which contains rigid and flexible ligand docking based on the geometric algorithms64. UCSF DOCK can be used to screen the small molecules subset of ZINC database directly. The LigandFit65, Glide66,67,68, GOLD69, MOE Dock and Surflex-Dock70 use the commercial licenses to service for drug virtual screening71,72,73,74,75,76. They show the powerful ability to screen the drugs from small molecule database through checking their citations on Google scholar. Moreover, wang et al. systematically summarize the advantage on the accuracies of binding pose and binding affinity of molecular docking software by comparing with five free academic license programs (LeDock, rDock, AutoDock, AutoDock Vina, and UCSF DOCK) and five commercial license programs (GOLD, LigandFit, MOE Dock, Glide, and Surflex-Dock)77. Furthermore, de novo drug design, which is another computer-aided method for drug discovery, can create the new ligands. LigBuilder78 and MOE Fragment-Based Design (www.chemcomp.com) are the representative de novo drug design software based on fragment linking and growing in the active pocket of targets. The computer-aided software has successfully applied into virtual screening studies and accelerated the process of drug discovery79,80,81. Besides, although the ligands can locate at the active pocket of receptor very well, they may not become the medicine due to the poor ADME (absorption, distribution, metabolism, and excretion)82. ADME can be used to build the computer modeling for the prediction of structure-property relationships and reduce the trial failure of drugs in the clinical phases83. The ADME of drugs can be predicted based on the supported molecular format files by Schrödinger or Discovery Studio software.
Table 3. Software of molecular docking and molecular dynamics simulations| Software | Description | Weblink |
| LeDock | Protein-ligand docking | www.lephar.com/software.htm |
| rDock | Ligands against proteins and nucleic acids | rdock.sourceforge.net |
| AutoDock | Protein-ligand docking | autodock.scripps.edu |
| AutoDock Vina | Protein-ligand docking | vina.scripps.edu |
| UCSF DOCK | Protein-ligand docking | dock.compbio.ucsf.edu |
| LigandFit | Protein-ligand docking | accelrys.com |
| Glide | Protein-ligand docking | www.schrodinger.com |
| GOLD | Protein-ligand docking | www.ccdc.cam.ac.uk/solutions/csd-discovery/components/gold |
| MOE Dock | Protein-ligand docking | www.chemcomp.com |
| Surflex-Dock | Protein-ligand docking | www.jainlab.org |
| Amber | Molecular dynamics simulations | ambermd.org |
| Gromacs | Molecular dynamics simulations | www.gromacs.org |
| NAMD | Molecular dynamics simulations | www.ks.uiuc.edu/Research/namd |
| CHARMM | Molecular dynamics simulations | www.charmm.org |
Molecular docking can perform the high-throughput screening on the huge of small molecule database, while molecular dynamics (MD) simulation is the low-throughput method to evaluate ligand binding pathways84. The software Amber85, Gromacs86, NAMD87, and CHARMM88 are four popular molecular dynamics package mainly designed for simulations of lipids, nucleic acids and proteins (see Table 3). MD software can be used to study the dynamical interaction between targets and ligands at the atomic level. It can profile more detail and accurate interaction information for ligands in the pocket of receptor than molecular docking. Especially, the Poisson–Boltzmann or generalized Born and surface area continuum solvation (MM/PBSA and MM/GBSA) give the good approaches to compute the binding free energy between ligands and biological macromolecules89. As the experiment reported90, MM/GBSA shows the faster and better prediction of binding affinities between ligands and targets than MM/PBSA in the absence of metal. MD simulations have become the popular method to study the mechanism of activated, inactivated states and ligand interaction on different targets, such as GPCRs91,92,93,94,95,96, ion channel receptors97,98,99, etc.
In vitro Biochemical Assays for Compound Screening
One advantage of drug design using high throughput assays and computational tools is that it can largely reduce the use of animals in activity testing. Furthermore, in vitro experiments complemented with computational methods have been extensively used in early drug discovery to select compounds with more favorable ADME and toxicological profiles100,101,102. Most commonly, drugs are organic small molecules produced through chemical synthesis, but biopolymer-based drugs (also known as biopharmaceuticals) produced through biological processes are becoming increasingly more common. In addition, mRNA-based gene silencing technologies may have therapeutic applications.
The predominant strategy used over the last decades consists, first of all, in clarifying the biochemical processes underlying a disease, then identifying an appropriate drug target and finally developing a suitable assay that allows the screening of chemical libraries for small molecules interfering with the target. Based on the various protein targets of diseases, multiple approaches including biological or in silico had been designed to screen new drugs towards the diseases treatment. These approaches are, however, very expensive and demand a great deal of background knowledge. For classical pharmacology, many chemical libraries of synthetic small molecules, natural products or extracts were screened in vitro or in vivo, such as intact cells, whole organisms or cell-free systems to identify substances that have a desirable therapeutic effect.
The early experimental process to approach drug discovery involves several well defined biochemical assays to screen those compounds that can interact or bind with certain binding partners, such as receptor/ligand binding analysis103, 104, enzyme-activity evaluation105, 106. In addition, techniques such as X-ray crystallography structural analysis107, 108, NMR109, 110, calorimetry111, 112, affinity chromatography113, 114, ELISA115,116,117 and protein mass spectrometry118, 119 are common strategic tools in protein-binding studies and play an important role to enhance the structural basis of rational drug design. These techniques aim to detect the separation of compounds from the studied proteins and monitor changes in intrinsic parameters of the targets upon forming a complex with tested drugs. Table 4 shows the biological assays used to detect the binding event between two binding partners, such as protein-protein, protein-nucleic acid, protein-small molecules. In the next, the applications of isothermal titration calorimetry (ITC) and Surface Plasmon Resonance (SPR) are reviewed in detail.
Table 4. Biological assays measuring the binding between macromolecules| Assays | Binding Partners |
| Surface Plasmon Resonance | Protein-protein, protein-DNA, protein-RNA, protein-drug, antibody-antigen, DNA-DNA |
| Enzyme-Linked Immunosorbent Assay | Antibody-antigen, protein-ligand |
| Isothermal Titration Calorimetry | Protein-protein, protein-drug, drug-DNA, protein-DNA, enzyme-substrate |
| Electrophoretic Mobility Shift Assay | Protein-DNA, protein-RNA |
| Thermal shift assay | Protein-drug, enzyme-substrate |
| Protein Fluorescence Quenching | Protein-drug |
| Differential Scanning Calorimetry | Protein-drug |
| Nuclear Magnetic Resonance | Protein-drug |
| Affinity Chromatography | Protein-drug |
| GST Pull-down | Protein-protein |
| Footprinting | Protein-DNA |
| Chromatin Immunoprecipitation | Protein-DNA |
The rapid development of science technology has prompted the emergence of several new approaches. Isothermal titration calorimetry (ITC) is one of the products of the rapid science technology development. It is most often used to investigate the binding of small molecules to larger macromolecules, such as proteins or DNA. In the measurement using ITC, several important parameters involving the binding process can be calculated, including binding affinity, enthalpy changes, and the binding stoichiometry. According to the obtained parameters, the final Gibbs energy changes and entropy changes can be specifically determined120, 121. As ITC gives not only the binding affinity, but also the thermodynamics of the binding interaction, it is typically used as a secondary screening technique in high throughput drug discovery to eliminate false positive hits after primary screening122, 123. Characterization of the binding thermodynamics allows further hit selection and lead optimization as ITC can provide insights into the structure-activity relationship (SAR) for ligand interaction with the target124, 125. Comparing to other techniques such as fluorescence assays and NMR for studying the complex formation, ITC does not need any fluorescent probes or radioactive tags for data analysis. In addition, proteins used in the measurement do not require chemical modification that is ease of use and cost. In spite of various advantages, low throughput, low sensitivity, and large sample requirement are major concerns, which may hamper its application126,127,128.
Another new technique is Surface Plasmon Resonance (SPR), which is the product of nano-science development. The emergence of SPR had greatly reduced the detection limit of biological analysis and it is widely used for the study of ligand binding interactions7, 129, 130. SPR is label-free in that a label molecule is not required for detection of the analytes and capable of measuring real-time quantitative binding affinities and kinetics in sequential binding events131, 132. Moreover, SPR is especially interesting as it can present kinetic information according to affinity data and can be used for thermodynamic studies133,134,135,136. At the same time, SPR biosensor assays can be applied in a wide range of proteins, including membrane proteins, such as G-protein-coupled receptors (GPCRs)137,138,139,140,141. Another application of SPR technology is early ADME (absorption, distribution, metabolism, and excretion) profile prediction for lead compounds in drug discovery trial142. SPR have the merits of real-time measurement, label-free and widespread biomolecules, it is emerging as an essential tool for drug development and has been widely used as a primary screening methodology for drug discovery125, 143, 144. During a SPR measurement, the information includes data about concentration of a binding partner in a mixture as well as kinetic rate constants (association, dissociation rate constants and the equilibrium dissociation constant) for the binding interactions145. Thus, SPR provides insights into the efficacy, safety, duration of action, indication, and patient tolerability of a drug.
Typically, in a compound screening campaign, the selection of evaluation means is highly depended on properties of the target to be studied146. In studies of prion diseases, researchers have proposed several methods to screen new prion inhibitors that would benefit prion-related patients. As prion protein is prone to convert from a dominantly soluble α-helix structure to β-rich insoluble pathogenic aggregates, efforts have been extensively made toward the aggregation dynamic process and discovery new compounds interrupting the aggregation147,148,149,150. Thioflavin T (ThT) can specifically bind to β-rich aggregates accompanying a red shift of the fluorescence emission spectra. Hence, it is frequently used as a dye to monitor the aggregation of prion protein151,152,153,154. Based on this knowledge, Li et al. evaluated the inhibitory effects of several compounds on prion aggregation using ThT as a detector155, 156. Once the aggregation process is interrupted or interfered by a compound, the increase and intensity of ThT fluorescence are delayed or weakened obviously indicating the efficiency of tested compound. Moreover, by combining multiple approaches in drug screening, it would provide more and much accurate information of the drug-target interaction profile. For example, ITC combined with chromatography has been used to identify and isolate unknown target proteins such as receptors or cell/tissue lysates127, 157. Overall, to conduct a successful drug discovery, the evaluation assays should be carefully selected according to different investigating targets.
In vitro Cell-based Approaches
As a common method used in drug discovery, cell-free systems have various advantages, such as fast, microscale and high throughput and the screening results are accurate and stable146, 158, 159. However, the molecular testing models are designed to specific target, which can only provide limited information about the target interactions. Moreover, the effects of certain drugs on an organism are complex and the interactions between two partners are involved in multiple levels that cannot be predicted using biochemical assays. Hence, single molecular high-throughput drug screening technology can no longer meet the needs of new drug discovery today. Then more biologically relevant cell-based screening assays have been developed and are widely used to predict responses of an organism to drugs160, 161. In addition, the cell culture is selected as a model system to predict cellular toxicity, which plays an important role in drug discovery process162.
Tumor cell lines are common cell models used in diseases investigation and drug discovery. Current cell-based models rely heavily on immortalized cell lines, usually derived from human tumors. These models have advantages, such as cost-effective scale up and well consistency. Table 5 displays common human-derived cell lines used in cancer-related investigations. For normal cell lines, they are usually used as controls and toxicology evaluations. Additionally, these cell lines are amenable to genetic engineering, permitting gain and loss of function analysis. While these models demonstrate advantages, they offer limited biological relevance when compared to the intact organ and primary cell types. Currently, primary cells and tissue slices are the gold standards for drug discovery, as they exhibit greater resemblance to the organ of interest163,164,165.
Table 5. Common human cell lines used in several cancer researches| Cancer Types | Normal Cell Lines | Cancer Cell Lines |
| Bladder | SV-HUC-1 | T24, 5637, J82 |
| Breast | DU4475, MCF10A | MCF7, SK-BR-3, HCC38,1590 |
| Colon | - | RKO, CW-2, CBZ, SW48, T84, HRC-6, HT-29 |
| Liver | HL-7702, QSG7701, THLE-3, L-02 | HepG2, Hep3b, HuH-6, Li-7, PLC/PRF/5, HB611, BEL-7404 |
| Lung | MRC-5, HLF-a, HFL1, WI-38, BEAS-2B | A549, NCI-H157, A427, NCI-H524, TKB-1, Lu-165 |
| Pancreas | HPC-Y5 | PANC-1, AsPC-1, HS766T, SW1990 |
| Prostate | WPMY-1, RWPE-1, RWPE-2 | DU145, LNCaP, PC-3, 22RV1, VCaP, 2B4 |
| Renal | HEK-293, HKC, 293FT | SW-13, A498, 786-O, Caki-1, 769-P, UT14 |
Human pluripotent stem cells hold great promise in research and medicine for their unique ability of self-renewing and differentiating to various cell lineages in the body. For different studies, human pluripotent stem cells can be controlled to differentiate to desired cell types to fulfill the investigation purpose166,167,168,169. As general cell lines used in drug screening present limited relevance to the organ of interest, stem cells provide exciting new models and bring new changes for drug discovery and development as well as drug toxicity testing to treat different human diseases170. As we known, it is still a great challenge for drug discovery to neurodegenerative diseases because the biological mechanisms are complex and poorly understood. The lack of models that accurately characterize these dysfunctions blocks further investigations. Fortunately, recent advances in stem cell technology offer researchers available tools to generate human neurons to develop disease resemble assays for small molecules screening. The emergence of adult tissues or cells derived induced pluripotent stem cells (iPSC), which bypass the need for embryos, promotes new investigations of stem cells. Bright et al.171 developed a specific antibody BMS-986168 for the Tau fragment based on human-induced pluripotent stem cells from patients with sporadic Alzheimer’s disease (AD). In 2017, this antibody was licensed by Biogen and entered Phase II clinical trials for AD treatment. Retigabine, another drug under clinical Phase II trial was also derived from iPSC models generated from amyotrophic lateral sclerosis (ALS) patients172. In addition, the recent advances in the production of stem cell-derived hepatocytes and cardiomyocytes combined with cutting-edge engineering technologies supplement the application of stem cells as an attractive alternative model for current drug discovery, which will deliver safer and more efficacious medicines for the patient173,174,175. Moreover, the use of stem cell-derived in vitro systems could reduce animal use and facilitate mechanisms investigation of the toxicants at the same time in toxicity evaluations170. Advancements in pluripotent stem cells and 3D culturing techniques promote the creation of organoids that can accurately recapitulate the properties of various specific subregions of many human organs. Tumor organoids resemble the original tumors much better than cell lines, having a 3D structure, a variety of cells, and similar growth characteristics, they can be applied as a pre-clinical cancer model for drug discovery176, 177. In addition, organoids provide another opportunity to construct cellular models of human diseases that can be used to deeply study the causes of diseases and further identify possible treatment in laboratory178, 179. We believe that advances in stem cell biology would provide more accurate human tissue and disease models for drug development.
In vivo Animal Models
Compared to in vitro screening, in vivo testing is better suited for observing the overall effects of an experiment on a living subject. As in vitro assays can sometimes yield misleading results with drug candidate molecules that are irrelevant in vivo, efficacy verification in vivo is especially crucial in drug discovery process. In addition, whole-organism in vivo screening holds several advantages to small molecule discovery for its target agonistic and holistic.
One of the most important and widely used model organisms in scientific research is zebrafish, which possesses numerous advantages and is the pioneer model for drug screening. It has been used in various research fields, such as gene expression and sequencing180, 181, cancer models182, 183, immune system184 and infectious diseases185, 186. Ongoing research programs have promoted zebrafish model to develop novel therapeutic agents in drug discovery. Drug screens based on zebrafish can not only identify novel classes of compounds with biological effects, but also discover novels uses or targets of existing drugs187. Using a zebrafish screen, a bioactivity from an extract of Jasminum gilgianum plant was discovered to induce the formation of ectopic tailbuds in larvae188. Similarly, some new targets of old medications were identified from zebrafish chemical screening, such as the phenothiazine antipsychotics, which was demonstrated to be toxic to MYC overexpressing thymocytes189. For the commercially available antiangiogenic statin rosuvastatin, a new function was discovered to suppress the growth of prostate cancer in a zebrafish screening of known bioactive compounds190. Other new compound classes were also identified based on zebrafish screens, such as GS4012191 and lenaldekar192.
Another vertebrate animal model frequently used in drug discovery are Xenopus frogs, which belong to the amphibians. As Xenopus frogs share a long evolutionary history with mammals, they are the excellent models to predict human biology. Xenopus have been extensively adopted as a convenient first-line animal model at various stages of drug discovery and development. Since the early 1980s, Xenopus embryogenesis has been much explored and a protocol termed frog embryo teratogenesis assay was applied to identify drugs that pose potential teratogenic hazards, including mortality and malformation193. Embryos and tadpoles were severed as versatile animal models to investigate blood vascular development and angiogenesis. Subsequently, Roland et al.194 uncovered pathways involved in the development of the lymphatic and blood vascular system in Xenopus tadpoles and discovered new compounds and pathways that were not previously known to mediate lymphatic or vascular development. Due to large number and size of the eggs, the rapid development of the embryos and the fact they are amenable to pharmacological, surgical and genetic techniques, Xenopus laevis has been successfully used in searching for embryonic signaling pathways targeting compounds195, particularly the Wnt/β-catenin pathway196, 197.
Despite successful application in drug discovery, the zebrafish and Xenopus models are largely different from the mammals in various aspects including genetics, immune system, and metabolism. Hence, more advanced mammal models were developed to decrease the gap between animal and human diseases, such as dog, rabbit, rat, mouse and the non-human primate Rhesus and Orangutan Monkey. In a research to determine the isolates of pancreatic secretion could be used to treat dogs with diabetes on an animal model dog, promoted the discovery of insulin and then the use in diabetes treatment198. For rabbits used as organism models, they are frequently used to produce antibodies in immunology199. In addition, rabbits are important models to study cardiovascular disease200. Guinea pigs are vertebrate models extensively used by early bacteriologists as hosts for bacterial infections and infectious diseases including viral and parasitic infections201. The mouse is one of the classical model vertebrates and has become the popular choice for developing various in vivo mammalian models as it shares about 85% genome identity to humans and has many physiological systems that are similar to those in humans. In addition, mouse has characteristics such as short life-cycle, techniques for genetic manipulation (inbred strains, stem cell lines, and methods of transformation) and non-specialist living requirements that are predominant and convenient to use. It is commonly used for scientific research in medicine, psychology and genetics202. Comparing to the mouse, the rat has larger size of organs and suborganellar structures and it is particularly used as toxicology models and neurological models203. While for the non-human primate Rhesus and Orangutan Monkeys, they are conventional animal models used in hepatitis, HIV, Parkinson's disease, cognition, and vaccines investigations204, 205. For different scientific research purposes, numerous animal models can be constructed. For example, human tumor xenograft, orthotopic/intratibial tumor models, murine tumor xenograft and patient-derived tumor grafts were built in nude mice or rats to investigate oncology development or screen new cancer drugs206,207,208. Using the constructed models, development of many human tumors including colon cancer, breast cancer, lung cancer, prostate cancer, ovarian cancer, renal cancer, cervical cancer, pancreatic cancer and melanoma has been investigated at different degrees. At the same time, therapeutic compounds targeting these tumors were also discovered either from the existing drugs or from new synthetic compounds.
Despite numerous models developed for drug discovery, most therapeutic drugs still fail in clinical trials. One of the reasons is attributed to sufficient clinical predictive power of our current model systems. Despite the high genetic similarities between human and mice, physiological differences affect the course of diseases in mice models when some genetic disorders in human do not have the same symptoms in mice. In addition, the cell lines and xenografts commonly used are inadequate models that can not highly mimic and accurately predict human diseases. Generally, for a drug discovery research in the laboratory, in combination with the chemical assays, cell-based and in vivo testing would perform more efficiently to obtain effective lead compounds for further drug development. At last, new models are still needed to be developed for scientific researches in the future.
Conclusions
As above review, the entire drug design process can be profiled from in silico, in vitro and in vivo experiments (see Figure 1). Our review summarizes the functions of macromolecular structure databases, small molecule databases, molecular docking software, de novo drug design software, MD simulations software, biochemical assays, cell-based system and animal models. This review shows the detailed individual component of drug design, and gives the comprehensive understanding for the progress of drug design.
Acknowledgments
The work is supported by the National Natural Science Foundation of China (Grant No. 21605066) and Fundamental Research Funds for the Central Universities (Grant No. lzujbky-2018-92).